How to Label Images and Train Models for Box Detection Applications
- 06 Feb 2024
- 13 Minutes to read
- Print
- DarkLight
How to Label Images and Train Models for Box Detection Applications
- Updated on 06 Feb 2024
- 13 Minutes to read
- Print
- DarkLight
Article summary
Did you find this summary helpful?
Thank you for your feedback
Box detection applications on the Cogniac platform work with a subject matter expert (SME) to label areas of interest in typical images. These areas of interest might be a defect on a manufactured part or an individual not wearing a hard hat on a construction site. Anything, good or bad, you can see in an image is a possible area of interest. A single box application can identify up to 20 different types of boxes at the same time.
This process of identifying the areas of interest is called labeling, and this tutorial will teach you how to label images in support of developing a box detection application. You can also watch this tutorial on the labeling process. The same process will also be used for labeling images for other applications on the Cogniac platform.
As you label images, this information is used to train Model that can be used to look at new images and determine if there are similar areas of interest: we call this process “inference”. As a rule, the more images you label, the better the models make inferences.
All of this happens on our CloudCore platform, our cloud computing platform. The models can then be deployed to an edge computing device like our EdgeFlow servers or Meraki MV cameras to allow inferences to happen with low latency.
This tutorial starts with a subject (a repository of images or video) filled with images of a grocery cart filled with common items one might find at a grocery store. We will build a box detection application that creates three output subjects: one filled with images of fruit, one with cereal, and the third with soda.
Before you start labeling, you must clearly define what goes into each category.
Fruit: Something is only labeled fruit if not packaged (e.g., a plastic clamshell of blackberries is not considered “fruit” for this tutorial). Also, we don’t consider tomatoes or avocados as fruit.
Soda: Fruit juice or cans of coke aren’t included, only 2-liter bottles of empty calories.
Cereal: Only boxes of cereal will be included, not bags of granola.
How you define each category isn’t important; it is only important that they are well-defined and consistently applied.
It’s critically important that the images you use for training come from the same environment as those you will later perform inferences on. If you take all of your images in a single US supermarket in March but you want to perform inferences in a supermarket in Chile in December, your real-world performance will be much less than predicted. Different fruits will be in season and popular, so the system will not recognize the fruits in your cart because it was never trained on them. The boxes of cereal and bottles of soda will look different and will also perform poorly. You might not do much better than random chance. This is the most important concern when labeling.
Creating applications is beyond the scope of this tutorial, but we recommend you watch this short tutorial.
In addition to this tutorial, you can view this:
Initial Labeling
Step 1: Log into your tenant at Cogniac.co
Double-click the application you want to train (in this case, “Grocery Cart”).

![]()

![]()
Step 2: Click “Replays”
“Replays” will play images stored in a CloudCore subject and run them through the model. There has been no training and no useful model for making inferences. We are just replaying images to set them up for providing feedback (aka labeling).
Select the source (i.e., the subject) of the training images (in our case, the subject Grocery Care has about 400 images of items in a grocery cart).
The number of images you want to replay and will be available for labeling (50 to 100 is a good starting point).
Select “Force Feedback”, which will make all of these images available for labeling in the feedback queue.
Click “Replay Subjects”

![]()
![]()
![]()
![]()
Some time will pass between starting the replay and images being available in the “Provide Feedback” queue for labeling
Step 3: Click “Provide Feedback”
The number in the yellow box (in this case, “100”) is the number of images in the queue available for feedback (i.e., labeling)

![]()
Step 4: Start labeling
So, let’s get started labeling our items!

![]()
Click the “+” sign to the right of “Fruit” to label the pineapple![]()

The box should be as tight around the object as possible.

![]()
And another box around the apple. There are no boxes of cereal or bottles of soda, so we’re done with this image. Hit “Confirm” to move to the next image.

![]()
The next image has none of our targets, so we “Confirm” without labeling anything.

![]()
In addition to clicking the “+” sign on the dialog box, we can type “n” and select which object we’re labeling. In this case, we’ve already labeled two apples as fruit and are about to label the box of cereal.

Now that we’ve labeled everything, we can “Confirm” and move to the next image.

For our labeling, avocados are not a fruit, and V8 is not a soda.

Note: Drawing a box around objects is a one-to-one relationship. For instance, each of the three oranges here gets its box.

In this image, most of the Frosted Flakes is obscured, but enough is visible to identify it as a box of cereal, so it is labeled as such.
As a rule, 50 images of each of your targets is a good starting point, though more may be necessary depending on the performance required, the quality of your images, and the target's subtlety.
Step 5: Model Training
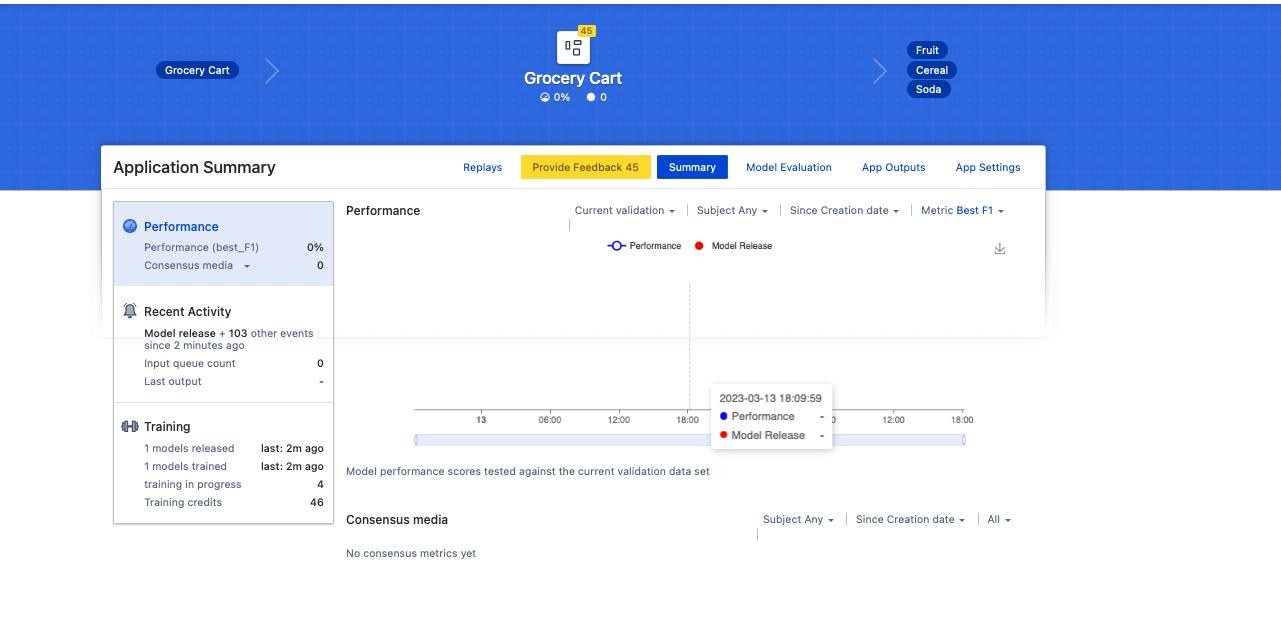
After labeling about 50 images, you can see your training credits have increased (now 46). This is a measure of how much labeling you’ve done. The higher your training credits (up to a maximum of 50), the higher priority the system will put in training models for this application (if you have a dedicated training instance, then the prioritization is less critical). As training progresses, your credits will decrease unless you do more training.
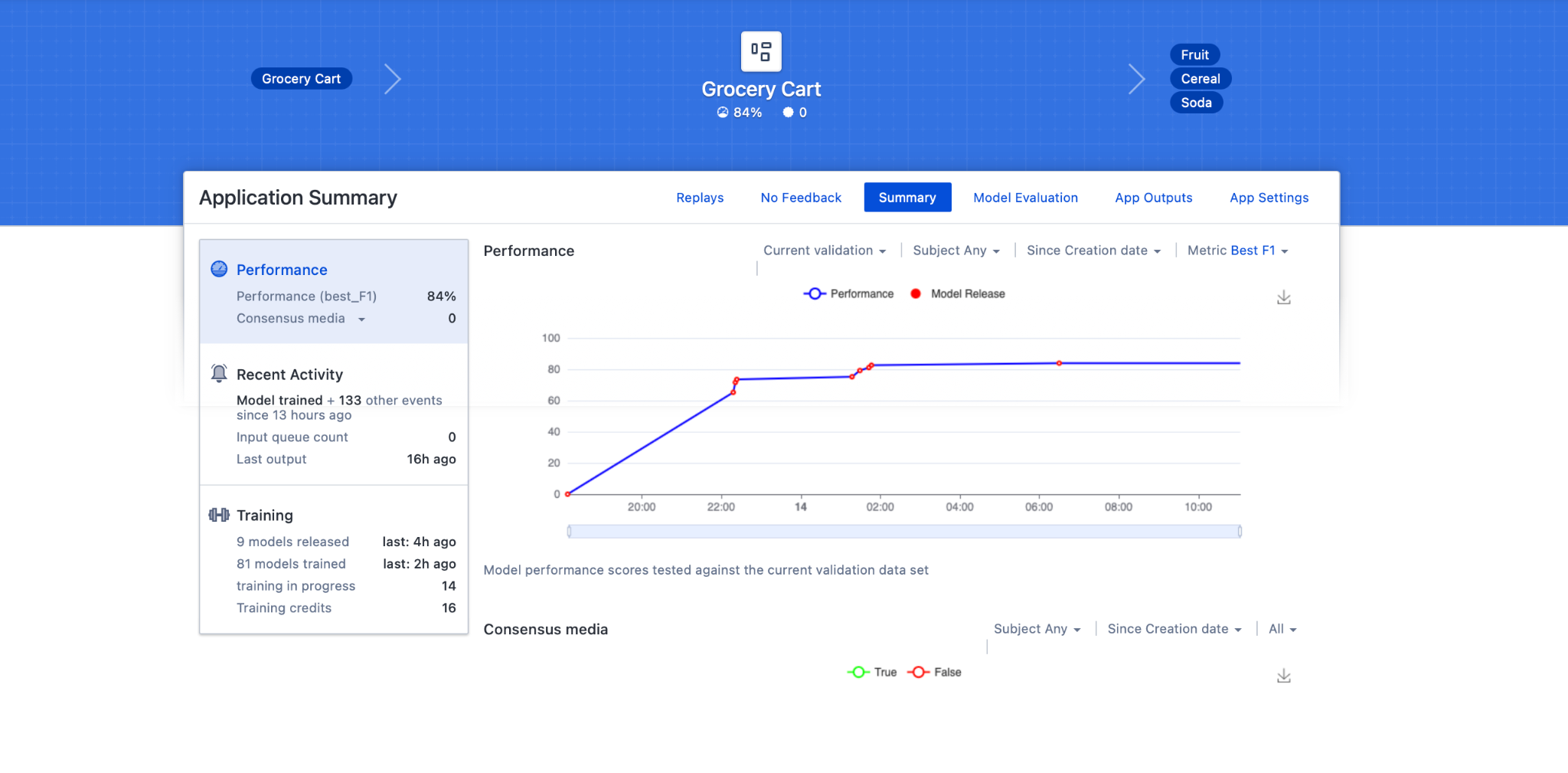
After several hours (your time will depend on whether you have dedicated training and the amount and complexity of your data), the platform has trained 81 models and released 9 of them. The platform releases a model whenever it performs better than the previous model (the metric is typically F1, which we will describe in detail later). Our current performance is 84%, which is good but not good enough.
Model Improvement
Step 6: Labeling for improvement
Though the platform is still training new models looking for better performance, we will replay more images just like before (Step 2) to provide the platform with more data, but there’s something new when we click “Provide Feedback” (Step 3). The model thinks it knows how to find our targets, and we’ll let the system know how well the model performs.

We see the model could accurately find five limes and three oranges. We step through all of these by clicking next. We can pause to delete any false positives (e.g., calling a tomato a “Fruit”).

Once we’ve finished the Fruit, we click “Done” and move to Cereal

The model did find the cereal. The box is bigger than needed, so we can tighten it, but at this point, that isn’t important. Click “Next” and “Done” to move on to Soda.

The model did a good job finding two bottles of Sprite.

Select “Done”, and we’ll see the full image with all the detections.

We could add anything we missed by typing “n” or selecting a “+”.
For this image, the model successfully found 7 pieces of fruit, one box of cereal, and two bottles of soda with no false positives. That’s impressive, with only 50 images for training. Now, let’s click “Confirm” and check out the next image.

The model found all the Fruit but no cereal or soda. We’ll need to add those (click on the “+” or type a “n”)

Now, we can confirm and move on to the next image.

The model labeled two tomatoes as Fruit, so we’ll need to “Delete All”

The model also identified a bag of chips as a cereal box, so we must delete that box.

Finally, it correctly labeled the bottle of Sunkist. Hit confirm to move to our next image.

Two well-labeled boxes of cereal.

And two well-labeled bottles of soda. Let’s look at one more image.

Three oranges and five limes were well-labeled.

One box of cereal labeled.

And two bottles of soda.
Now, we’ll let the system train some more models.
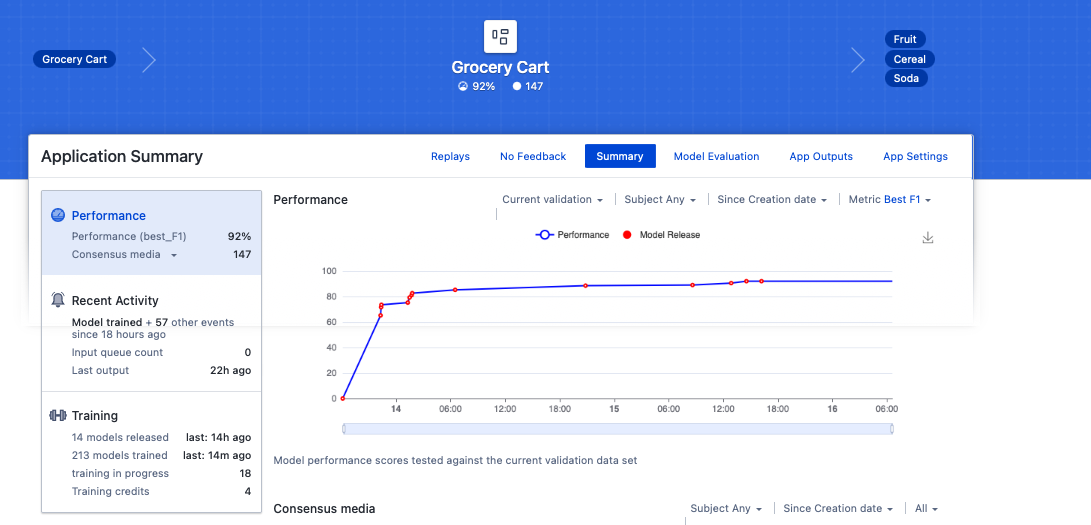
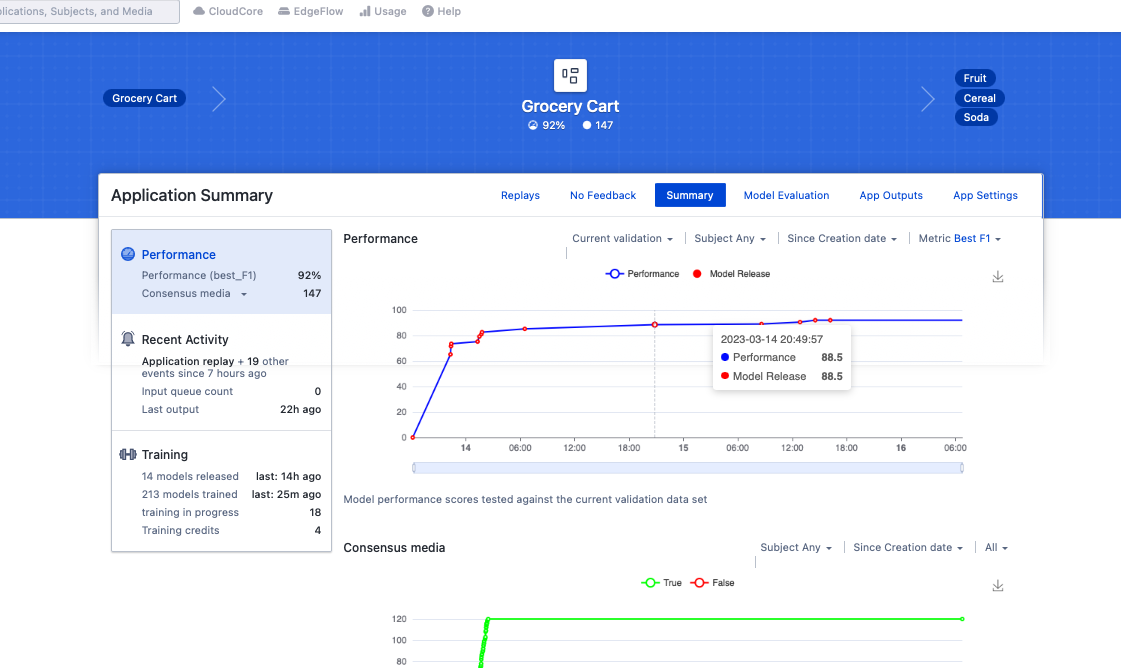
After about two days (your time could be significantly different, especially if you have a dedicated training instance), our performance has increased to 92% based on labeling 147 images. The platform has trained 213 models to get to this level of performance. But we can still do better without having to label another 150 images manually.
Step 7: Iron Fist
Once you have an application in the Cogniac system with 100+ labeled media, you’ll see declining returns from just labeling random images.
If you have a large dataset, you can mine it for the hardest images to force the model to learn harder. We call the technique of labeling and forcing the model to learn the hardest examples the “Iron Fist” technique.
This technique relies on the notion that at any given time, the hardest images for a model are the images for which its predictions are “most wrong” (i.e., have the lowest probability of being correct.. These are also the most valuable images to label, forcing the model to “learn harder”.
The technique is as follows.
Replay ALL (or up to 1000 RANDOM) images from the input subject.
You want to draw from the largest sample pool to find the hardest to inference images. The system will automatically ignore media already labeled in your target application. The real purpose of this step is to update the model predictions in the output subject based on the current best model. This is necessary to find the ‘worst-of-the-worst’ predictions (i.e., lowest probability) from the current best model against the largest possible dataset.
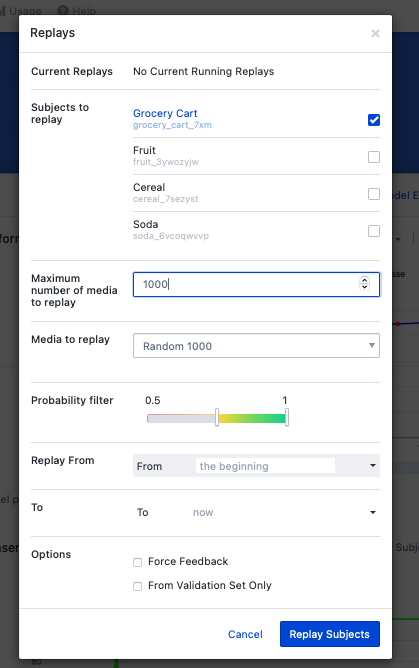
Unlike the previous times we’ve run “Replay”, “Force Feedback” is not checked. By setting the maximum number of images to replay to 1000, we guarantee that all unlabeled images will be run through our current model since there are only 400 images in the subject “Grocery Cart”.
Wait for the replay to complete
Check the output subject (with the probability filter set to full range 0 to 1) and refresh until no new output items appear.
Fruit was selected because it’s the most common of our three outputs, though the process would work with any of the output subjects.
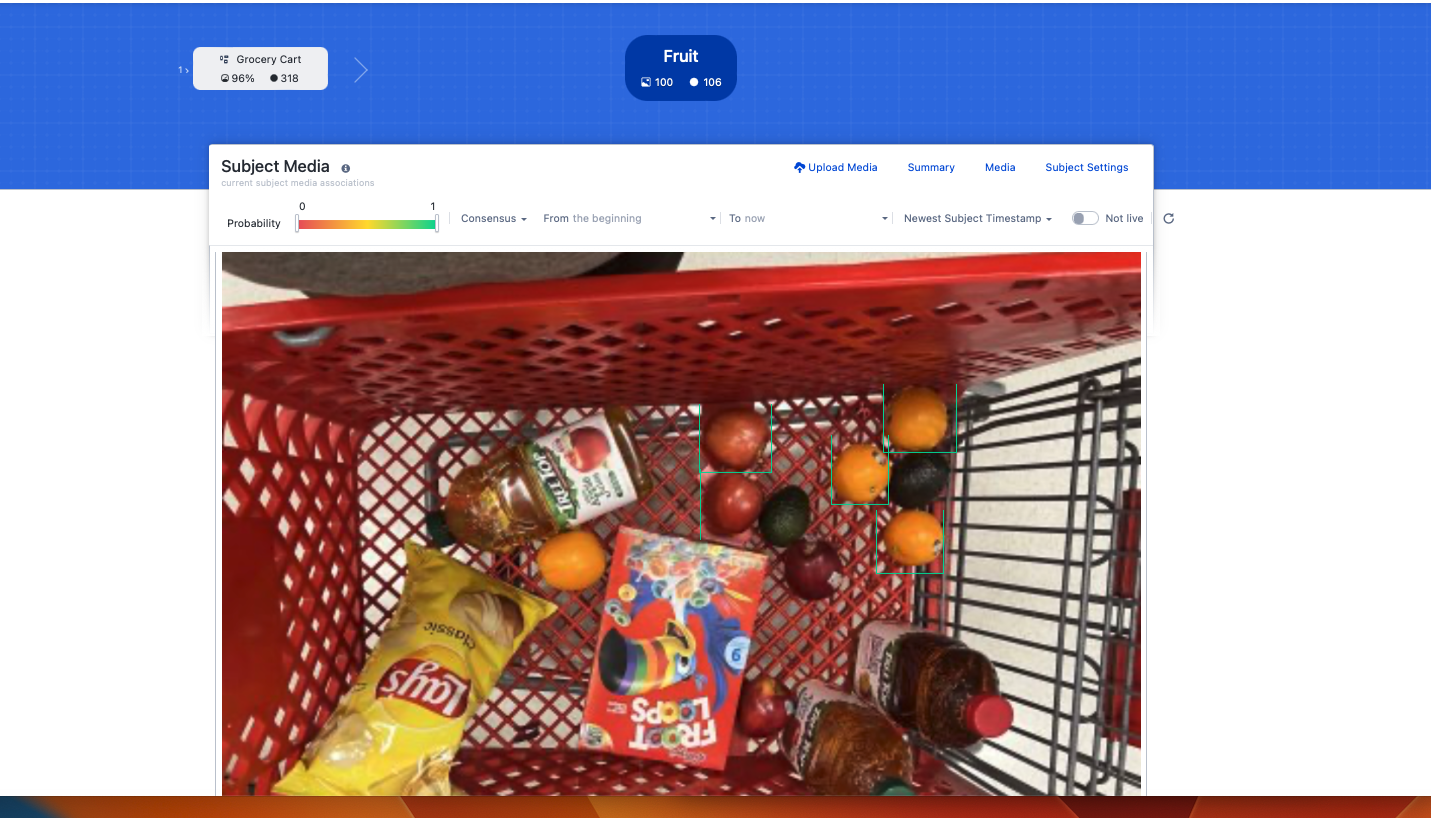
Keep refreshing the image until new images stop appearing. Since the tenant only performs inferences and not model training, this doesn’t take long (minutes, not hours).
Prepare to replay again the most difficult items by selecting a probability range for the most difficult samples in a single subject
For example, if finding a region-of-interest (ROI) and most images are expected to have the ROI, select a probability range of 0 to ~0.5, which contains the ‘most wrong’ predictions.
In other cases where the ROI is not always present, the ‘most wrong’ range might be closer to [~0.4, ~0.6], for example. Look at the output subject of interest and adjust the probability range to visually check the results of selecting a particular probability range.
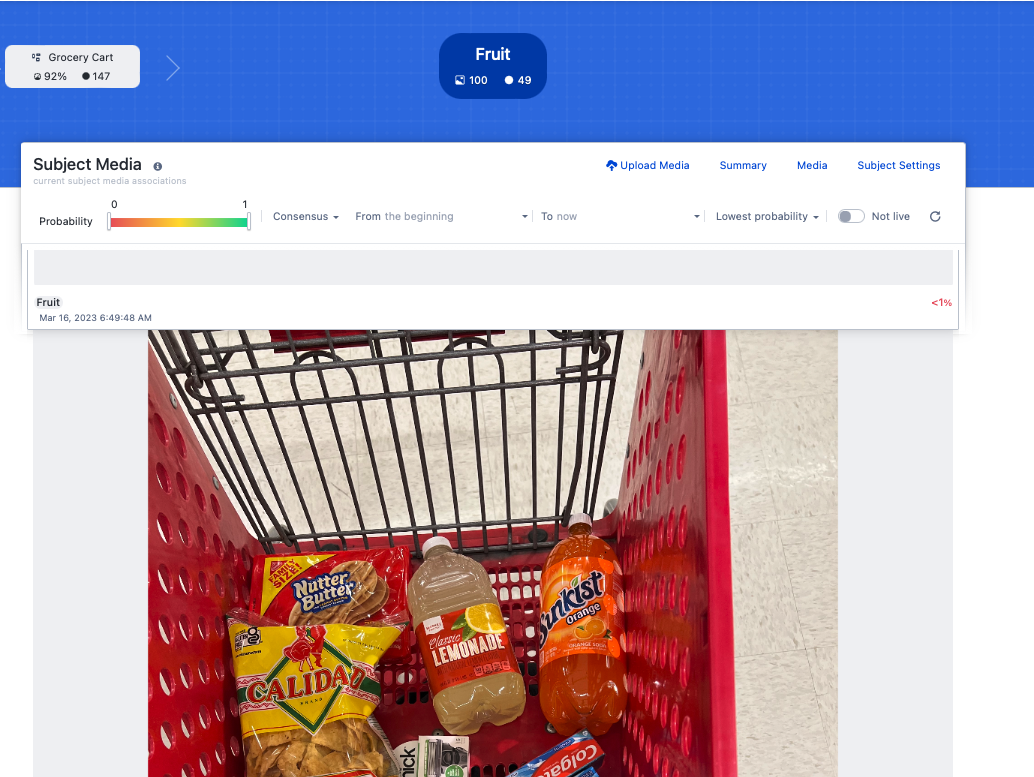
You can get a sense of the probability range to use by sorting on the “Lowest probability” and setting the probability range from 0 to 1, then clicking on the image.

Here, we see the lowest probability image is a true zero: no fruit is present. We can click to see the next lowest probability image until we see a false negative.
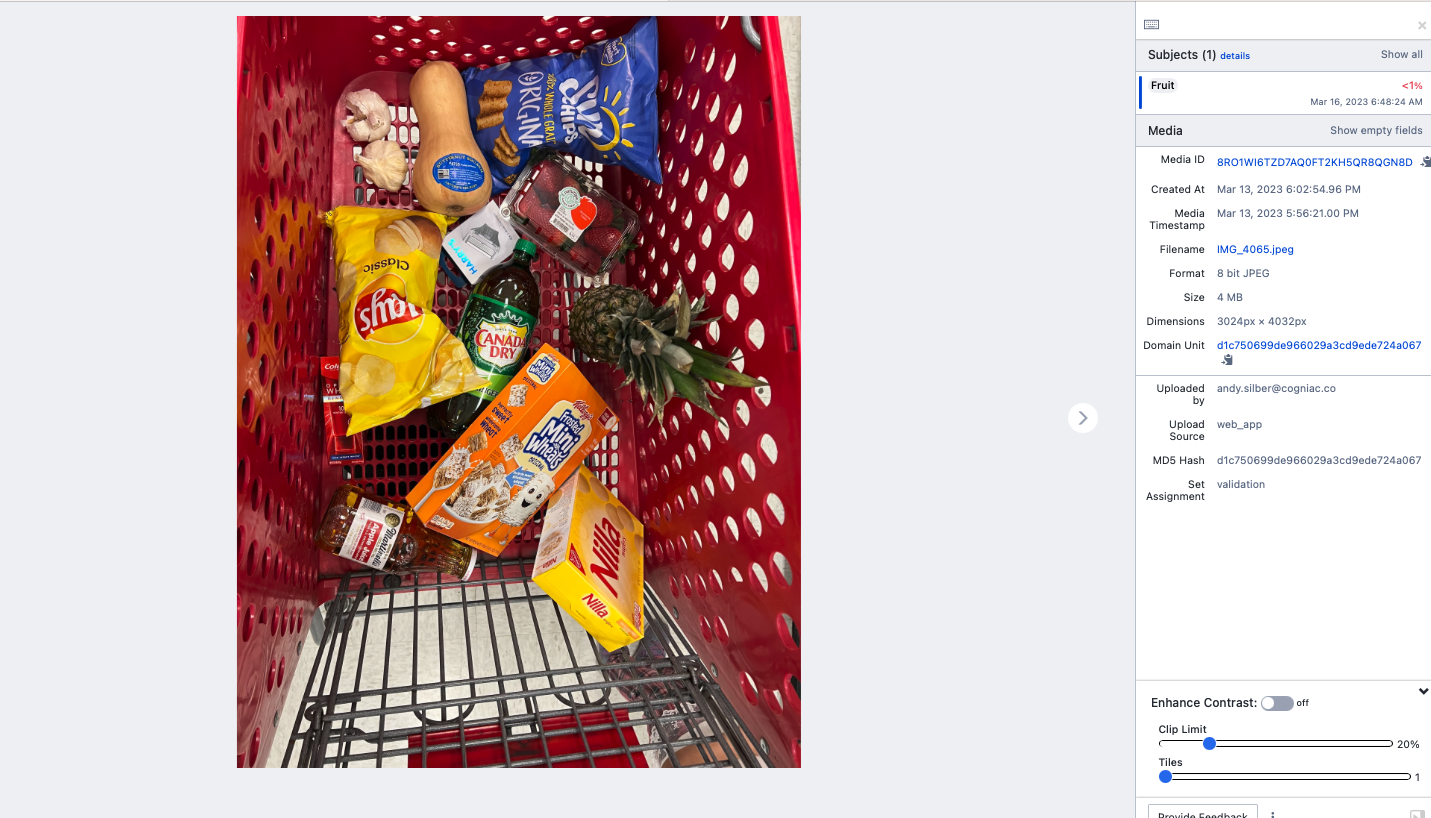
Here, we see the model completely missed the pineapple, so we should not filter on probability when we replay the “Iron Fist”.
In the case of OCR apps, the images with the lowest probabilities will tend to be the hardest samples.
Replay your application from an output subject(s) with a probability filter selected to contain the ‘most wrong’ (i.e., lowest probability) outputs.
Configure the replay for 25 to 50 images and “force feedback”.
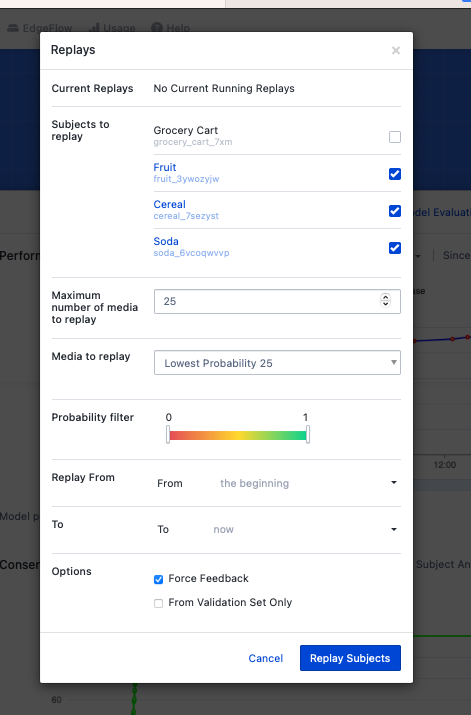
We use our output subjects as our input because that’s where the images have inferences attached to them. We’re going to run the 25 images with the lowest probability. If most of the images with zero probability were good (e.g., an empty cart), then we should exclude those with the probability filter. And finally, as usual, we select “Force Feedback”.
Wait for the replay to complete.
It may take some time if you have many items in the output subject., but not very long
Provide feedback on the “most wrong” images from the feedback queue.
Ruthlessly rule the model with your “Iron Fist”!
Wait for new models to be released and repeat if necessary.
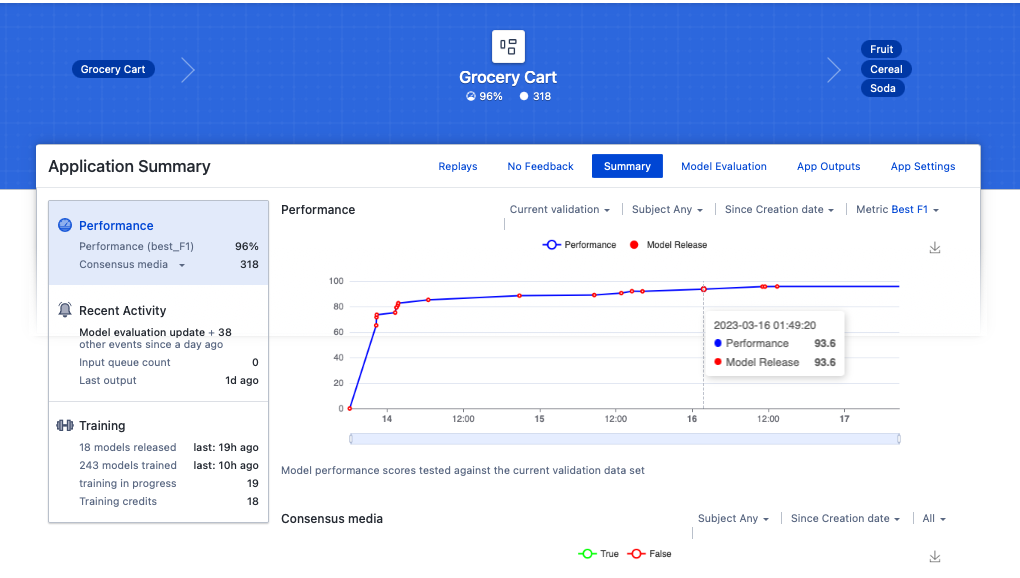
In our example, the performance increased from 92% to 96%.
Note: When utilizing the Iron Fist technique (or any labeling strategy that emphasizes harder images), the application accuracy reported by the Cogniac system may be much lower than the actual real-world application accuracy. Because the application is assessed on a random subset of the labeled images, you effectively make the application test a sample set more difficult than ‘real-life’ by labeling mostly the hard images. This is good because the more difficult training and validation set forces the model to “train harder”. As a result, it will perform better in the “real world” than the application accuracy indicates.
Model Evaluation
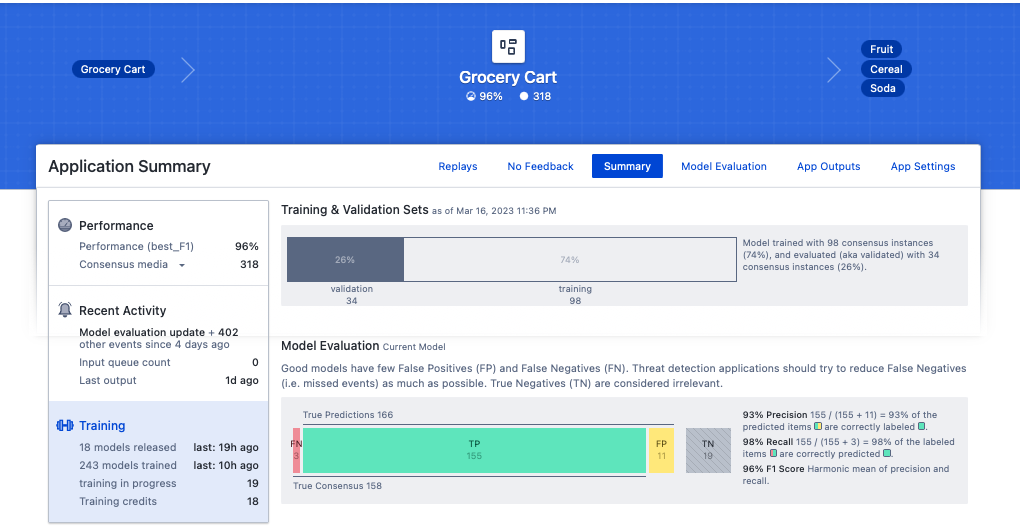
By selecting the training box on the left, we can see information about the model evaluation (also called validation). Of the 132 labeled images, 98 were used for training, and 34 were reserved for validating how well the model works. Of the 169 objects used for validation, 155 were true positive (TP), meaning the model detected actual targets. Only three objects were false negative (FN), meaning that real targets were undetected. Only eleven false positives (FP) detections were either nothing or the wrong object. So, the F1 score is reduced by both false positives and false negatives. In the App Settings, you can change the platform to optimize models with low false positive rates (i.e., precision) or low false negative rates (i.e., Recall). However, we don’t recommend this unless your use case is not sensitive to false positives or negatives.
Keyboard shortcuts
You will see a list of keyboard shortcuts if you click the keyboard icon in the upper right. Some of the most helpful are:
“l” - which lightens the image
“Shift + l” - which darkens it
“n” - which lets you label a new object (instead of clicking the “+”)
“Delete” - delete a detection or labeling box
Was this article helpful?